Introduction au machine learning
Vous avez-peut-être entendu parler de machine learning, deep learning ou apprentissage automatique ? Voici un aperçu de l'utilité et du fonctionnement de cette formidable technologie.
S'il y a une technologie à la mode, c'est bien le machine learning. Sans vraiment connaître les détails, vous avez peut-être entendu dire qu'il s'agissait des techniques permettant quelques exploits comme la conduite autonome, la reconnaissance vocale, le traitement du langage naturel, la reconnaissance d'image, la traduction automatique, la conquête du jeu de Go, etc. Rien que ça ! Autant de prouesses encore impensables il y a à peine quelques années.
Il faut dire que quelques avancées technologiques ont eu lieu en 2016 qui offrent aux scientifiques et ingénieurs de nouvelles possibilités. Sans compter que la plupart des GAFAs libèrent les uns après les autres le code source de frameworks comme TensorFlow, CNTK ou PaddlePaddle.
À mon grand dam, je n'ai quasiment pas trouvé d'introductions généralistes au machine learning qui ne nécessitent pas déjà de bonnes bases en calcul différentiel et algèbre linéaire, disciplines à la vénérabilité incontestée mais ne suscitant pas chez moi une appétence démesurée.
Alors, en quoi consiste le machine learning ? Y a-t-il une différence avec le deep learning ? Quel est donc tout ce binz ?
Un problème Willem ?
Un ordinateur est un outil et comme tous les outils, son utilité première est
de détruire des emplois résoudre des problèmes.
Exemple de problème : je voudrais consulter un plan de ma ville pour repérer l'itinéraire le plus court (ou le plus joli) entre mon lieu de travail et ma boulangerie préférée et peut-être vérifier s'il ne se trouve pas un primeur sur la route, parce que mon panier à légumes est vide.
Un ordinateur n'apporte des solutions qu'à partir du moment ou il a été programmé par des humain·e·s pour le faire.
Ainsi, ce sont des humain·e·s qui ont assemblés les milliers (millions ?) de lignes de code permettant à OpenStreetMap de fonctionner : je peux utiliser ce site pour afficher une carte, effectuer une recherche d'itinéraire, visualiser les commerces dans une rue donnée, etc.
Un projet comme OpenStreetMap (comme n'importe quel logiciel non trivial) est probablement relativement complexe. Heureusement, une telle complexité n'est pas un obstacle pour les fièr·e·s ingénieur·e·s dont je fais partie, puisque nous disposons d'une méthode redoutablement efficace pour attaquer ce genre de problèmes : nous le découpons en sous-problèmes.
« Créer un site cartographique » est en soi une tâche insurmontable, mais elle est en fait triviale si je la découpe en sous-tâches :
- réunir des données cartographiques ;
- les afficher sur un site ;
- créer un algorithme de recherche d'itinéraire.
Boum ! fini ! Évidemment, je n'ai fait que déplacer le problème, puisque « créer un algorithme de recherche d'itinéraire » n'est pas franchement une tâche triviale. Qu'à cela ne tienne, je n'ai qu'à la re-découper, puis re-re-redécouper jusqu'à obtenir des sous-sous-tâches suffisamment simples pour que je puisse effectivement les traiter.
Diviser pour régner
Ce mode de travail fonctionne étonnamment bien dans la plupart des cas. Créer une encyclopédie consultable depuis toute la planète et modifiable par tout le monde ? Fait ! Convertir du texte en impulsions électroniques et les faire voyager jusqu'à l'autre bout du monde pour les déposer dans la boîte de messagerie de votre destinataire ? Fait ! Lire des fichiers constitués uniquement de 0 et de 1 et les transformer en concerto de Vivaldi ou en riff d'ACDC ? Facile !
Ces tâches sont à notre portée car elles sont découpables en micro-instructions qui, exécutées séquentiellement par des ordinateurs idiots, auront un résultat déterminé à l'avance.
Il existe pourtant certaines tâches pour lesquelles cette approche ne fonctionne pas. L'exemple emblématique est celui de la reconnaissance d'image. Imaginons que je vous donne pour mission de construire un logiciel de détection de chaton dans des photos. À partir d'une bête photo, votre logiciel doit indiquer si oui ou non elle contient la représentation d'un chaton.
Pour un cerveau humain, il s'agit d'une tâche triviale effectuée instantanément et ne demandant pas la moindre once de réflexion consciente. Mais pour un ordinateur ? Comment découper ce problème en sous problèmes ? Essayons !
Détecter un chaton dans l'image ->
- détecter la présence de pelage
- détecter la présence de moustaches
- détecter la présence de pâtes poilues
- détecter la présence d'une queue
- détecter de grands yeux mignons.
Mouais… Et si sa queue est cachée ? Et s'il s'agit d'un chaton sphynx sans poils ? Et comment vais-je détecter de grands yeux mignons ?
Détecter de grands yeux mignons ->
- détecter la présence d'un œil
- vérifier qu'il y en a deux à peu près côte à côte.
Et si mon chaton se trouve de profil ? Et s'il à les yeux fermés ? Et d'abord, comment je détecte un œil ?
Détecter un œil ->
- détecter la présence d'une cornée
- détecter la présence d'une pupille.
Détecter une cornée ->
- ???
Quelle que soit la manière dont je m'y prenne, il semble que je me retrouve dans une impasse face à une tâche impossible. Au lieu de simplifier notre problème initial, ce découpage ne semble que le rendre plus complexe.
L'apprentissage machine à la rescousse
Pour sortir de l'impasse, il nous faut une autre approche. Et la solution qui donne les meilleurs résultats aujourd'hui, c'est le machine learning.
Le principe est le suivant : je vais partir du principe qu'il existe une fonction h(X) -> y avec X la liste des pixels de l'image et y la réponse (chaton ou pas). Vous pouvez imaginer h comme une fonction mathématique ou comme une fonction informatique codée dans le langage que vous voulez, ça ne change pas grand chose.
Je sais que cette fonction existe, parce qu'elle est contenue quelque part dans mon cerveau, mais je ne sais pas ce qu'elle contient, simplement qu'elle va effectuer des calculs à partir de la valeur des pixels pour recracher un simple résultat, chaton ou non, true ou false, 1 ou 0.
Cette fonction, puisque je ne peux pas l'écrire, je vais grosso-modo laisser l'ordinateur le faire lui-même, en faisant passer mon machin par une phase d'apprentissage (d'où le terme machine learning). Je vais réunir des milliers d'images de chatons et de trucs qui ne sont pas des chatons et les faire passer dans ma fonction. À chaque fois, je vais comparer le résultat obtenu (qui dans un premier temps sera du grand n'importe quoi) avec le résultat attendu, et chaque fois que la fonction se trompera, un algorithme très intelligent, fort en maths et impossible à expliquer en une phrase ira bidouiller l'intérieur de la fonction pour minimiser la différence entre ce que je veux et ce que j'obtiens.
Si j'ai bien fait mon travail, à la fin de cette phase, j'obtiendrai une fonction h devenue relativement compétente dans la reconnaissance de chatons. La réalité est évidemment beaucoup plus complexe, mais le principe est là.
Concrètement, je fais quoi ?
Pour mettre en place du machine learning, il nous faut plusieurs éléments.
Un problème
Nous cherchons à résoudre un problème, qui doit être énoncé clairement. Le machine learning permet grosso-modo de résoudre deux grandes familles de problèmes :
- la prédiction de valeurs en fonction de paramètres (on parle de régression au sens mathématiques du terme) ;
- la classification, e.g l'assignation de catégories en fonction des paramètres de départ.
Exemples :
- en fonction de la surface, prédire le prix d'un appartement dans le centre ville de Montpellier (régression) ;
- en fonction de son contenu, indiquer si un email doit être classifié en spam ou pas (classification) ;
- en fonction des informations fournies par les capteurs, indiquer à quel degré tourner le volant (régression) ;
- en fonction des pixels de l'image, classer la photo en chaton ou pas chaton (classification).
Un modèle
Le modèle correspond à la fonction utilisée pour résoudre le problème. Il faut bien entendu choisir une fonction adéquate.
- si je veux modéliser le prix d'un appartement en fonction de la surface, ma fonction prendra un seul paramètre (la surface) et retournera peut-être une droite.
- si je veux classer un email en spam / non spam, ma fonction prendra probablement une poignée de paramètres (longueur du mail, présence du mot « viagra » ou pas, présence ou pas de l'expéditeur dans mon carnet d'adresse, etc.) et retournera un booléen.
- si je veux classer une photo en chaton / pas chaton, ma fonction prendra des milliers de paramètres (un par pixel).
Je sais, j'ai dit que cette fonction allait s'écrire toute seule, mais j'ai menti.
Si je devais modéliser le prix d'un appartement au centre-ville de Montpellier en fonction de sa surface, utiliserais-je une droite ou une courbe ? Si je choisis une droite, peut-être que ma fonction h va s'écrire sous la forme h(x) = ax + b, alors que si je choisis une courbe, peut-être que ma fonction s'écrira sous la forme h(x) = ax + b * sqrt(x) + c.
Le machine learning va me permettre de déterminer les constantes optimales (a, b, c) de la fonction choisie, mais c'est à moi de sélectionner la fonction (le modèle) adéquate.
Vous vous dites peut-être que du coup, on en revient à devoir écrire nous même une fonction de reconnaissance de chat, ce qui devient tout de suite moins intéressant. Heureusement pour nous, il existe certaines techniques pour modéliser des problèmes (très) complexes d'une manière (relativement) simple (spoiler: les réseaux de neurones, on en reparlera).
Une fonction de calcul d'efficacité (calcul de coût)
Le modèle sélectionné va permettre d'effectuer des prédictions. Comme l'intérieur du modèle est initialisé au hasard, nous allons au début obtenir des résultats farfelus. Dans l'exemple de l'immobilier à Montpellier, peut-être que j'obtiendrai un truc du genre h(50) = -840334.
Pour que notre algorithme puisse apprendre, il lui faut un moyen de calculer à quel point il se gourre dans ses prédictions. Pour ce faire, nous définirons une fonction appelée fonction de coût (traditionnellement notée J), dont le résultat diminuera d'autant plus que le modèle prédit des valeurs qui s'approchent des observations.
Il existe différentes fonctions consacrées selon les besoins, mais nul besoin de rentrer dans les détails ici.
Des données d'apprentissage
Pour que notre modèle puisse s'adapter lors d'une phase d'apprentissage, il lui faut de la matière pour potasser. Nous aurons besoin de réunir un jeu de données suffisant étant donnée la complexité du problème. C'est souvent la partie la plus ardue, car s'il ne devrait pas être trop complexe de réunir quelques dizaines de milliers de photos de chatons, essayez donc de faire de même avec le fennec du désert albinos, pour voir.
Un algorithme d'apprentissage
Une fois que nous avons notre modèle, que nous sommes en mesure d'évaluer grâce à une fonction de coût et des données de test, il devient possible d'optimiser ledit modèle grâce à un algorithme d'apprentissage. Le but de cet algorithme est d'adapter le modèle jusqu'à ce qu'il établisse des prédictions conformes aux données de test, ce qui revient à minimiser la fonction de coût.
Il existe différents algorithmes d'apprentissages, et même le plus simple d'entre eux nécessite de se prendre la tête avec des notions mathématiques pas simples. Heureusement, il n'est pas forcément nécessaire de comprendre cet algorithme pour mettre en place du machine learning : il suffit de le traiter comme une boîte noire en sachant qu'il fait ce qu'on lui demande.
En résumé
Concrètement mettre en place une technique de machine learning consiste à choisir un modèle (une fonction) apte à résoudre un problème donné, et à paramétrer ce modèle correctement au cours d'une phase d'apprentissage qui met en œuvre une fonction de coût (souvent déjà définie pour vous), des données de test et un algorithme d'apprentissage (là aussi déjà écrit pour vous).
Machine learning, deep learning, neural networks?
« J'ai entendu parler de deep learning. Qu'est-ce ? »
Pour un problème donné, le modèle peut être très simple (une bête fonction h(x) = ax + b) ou très complexe (une grosse fonction qui prend des milliers de paramètres avec un niveau d'imbrication très profond).
Plus le modèle est complexe, et plus il sera capable de résoudre des problèmes complexes. La fonction f(x) = ax+b ne peut pas apprendre à conduire. Logique.
Il est évident qu'il est plus facile et plus rapide de calibrer un modèle simple qu'un modèle complexe.
Le deep learning est simplement un buzzword qui désigne la capacité (relativement récente, tant au niveau des algorithmes disponibles qu'à la puissance de calcul) à entraîner des modèles très complexes.
En gros, si vous voulez ajouter +20% à votre salaire, remplacez machine learning par deep learning sur votre CV.
« Et les réseaux de neurones, c'est quoi ? »
Un réseau de neurone est simplement une abstraction intéressante qui permet d'imaginer et de représenter simplement des fonctions très complexes.
Par exemple, ceci :
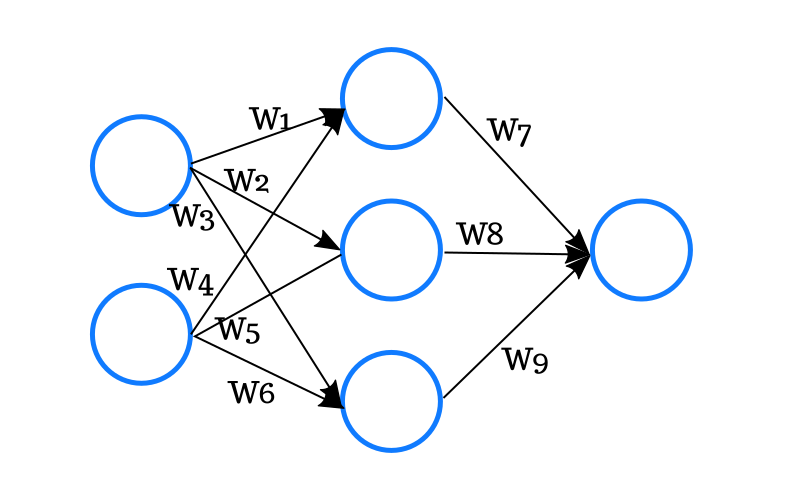
Est une manière agréable de représenter la fonction :
h(x) = g(W7 * g(W1 * x1 + W4 * x2) + W8 * g(W2 * x1 + W5 * x2) + W9 * g(W3 * x1 + W6 * x2))
Avec g(x) = 1 / (1 + exp(-x))
Et W1, W2… les fameux paramètres à calculer.
Je vous laisse imaginer avec quelques milliers, voire millions de neurones.
Au secours, les machines vont prendre le contrôle !
Les réseaux de neurones et le deep learning vont-ils prendre le contrôle de l'humanité ?
Ce n'est pas demain la veille. Un modèle, aussi complexe soit-il, n'est pas intelligent, et reste une pure fonction mathématique, non un être doué de raison et de conscience.
En revanche, il est toujours perturbant de constater à quel point un modèle constitué de l'imbrication d'à peine quelques milliers de neurones est capable d'exceller à des tâches qui nous paraissaient jusque là insurmontables, e.g la reconnaissance de l'écriture humaine.
Bref
Pas grand choses de concret dans ce billet bourré d'inexactitudes et d'approximation, mais j'espère avoir apporté quelques éclaircissement sur les concepts de base du machine learning.
Edit : la suite est ici